· Fanpeng Kong · Data Platform · 13 min read
Build a Modern Data Lakehouse Using IaC and CI/CD
How to build a production-ready Azure Databricks Lakehouse with Terraform, automated CI/CD, and Unity Catalog governance.
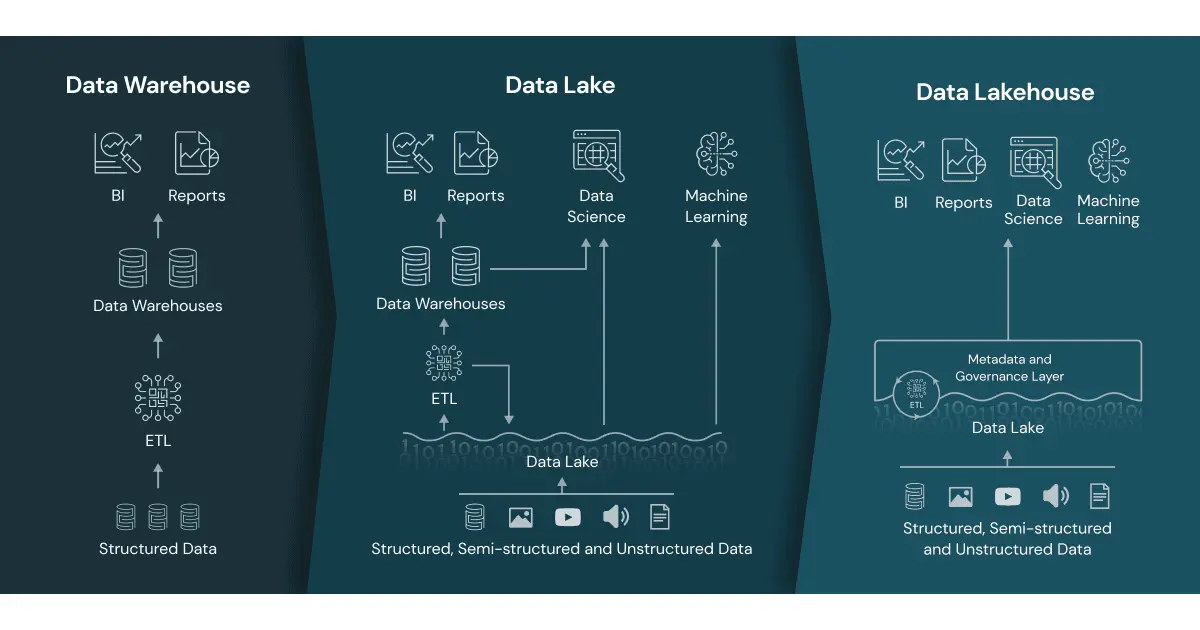
Table of Contents
Introduction
Over the past two decades, data platforms have evolved significantly - from the rigid, schema-on-write data warehouses of the 2000s, to the flexible but often ungoverned data lakes of the 2010s, and now to the modern lakehouse architecture. A lakehouse combines the reliability, governance, and performance of warehouses with the scalability and cost efficiency of lakes. This unified approach enables organizations to manage both structured and unstructured data while supporting real-time processing, advanced analytics, and AI workloads.
This capability has become especially critical with the rise of generative AI and large language models (LLMs). In 2025, successful enterprises are standardizing on unified lakehouse platforms - such as Databricks Lakehouse - to deliver both agility and enterprise-grade control.
But designing a lakehouse is only half the challenge. Operating it reliably across multiple environments (dev, staging, prod) requires automation, consistency, and strong governance. This is where Infrastructure as Code (IaC) plays a pivotal role. While provisioning a single Databricks workspace manually is manageable, scaling the same configuration across environments quickly introduces drift and compliance risks. Using Terraform, every workspace, storage account, and Unity Catalog configuration can be defined in code, enabling:
- Consistency – Environments are deployed identically, reducing “it works in staging but not in prod” issues.
- Security – RBAC, cluster policies, and storage access are reproducible and auditable.
- Collaboration – Infrastructure changes follow modern software practices: pull requests, code reviews, and CI validation.
This shift turns infrastructure from manual configuration into collaborative software development.
What you’ll learn in this post:
- Modern lakehouse architecture patterns on Databricks
- Multi-environment setup (dev, staging, prod)
- Unity Catalog governance and security implementation
- Infrastructure as Code (IaC) deployment with Terraform
- CI/CD best practices for automation
Databricks Lakehouse Architecture Overview
Databricks, built on Apache Spark, provides a scalable compute engine that is decoupled from storage. The lakehouse architecture unifies data warehousing and data lake capabilities—enabling organizations to handle streaming, batch, machine learning, and business intelligence workloads within a single governed platform. This eliminates the need for complex data movement or integration across multiple systems.
Two key technologies underpin this architecture:
- Delta Lake – An open-source storage format that brings ACID transactions, schema enforcement, and performance optimizations to data lakes.
- Unity Catalog – A centralized governance layer for metadata and access control, providing fine-grained permissions, auditing, data lineage, and discovery across workspaces.
Medallion Architecture and Landing Layer
A common design pattern in lakehouse environments is the Medallion Architecture, where data is progressively refined as it moves through layers:
- Bronze – Raw data from source systems such as APIs, files, or event streams.
- Silver – Cleaned and validated data with applied quality checks and standardized schemas.
- Gold – Aggregated, business-ready data optimized for analytics, dashboards, and reporting.
An optional Landing Layer is often included as the very first stage, where data is dropped exactly as received from source systems—unprocessed and in native formats. By contrast, the Bronze layer is the formal entry point to the Medallion Architecture, where data from the landing layer is ingested, standardized, and registered as raw but unified assets.
Unity Catalog Naming Conventions
Unity Catalog uses a three-level naming structure: <catalog>.<schema>.<object>. Establishing and enforcing consistent naming conventions across these levels is essential to avoid ambiguity, simplify governance, and support multi-environment deployments (e.g., dev, staging, prod).
Two practical naming patterns are commonly adopted:
- Catalog per Medallion Layer and Environment – e.g.,
bronze_dev,silver_staging,gold_prod.
This approach provides clear data-lifecycle separation and simplifies access control by data maturity. - Catalog per Subject Area and Environment – e.g.,
finance_dev,sales_staging.
This model supports domain-driven ownership and governance.
Within each catalog:
- Schema typically represents a team or processing stage (e.g.,
finance,bronze,gold). - Object represents a dataset, such as
ordersoragg_sales.
Storage in Unity Catalog
While Unity Catalog governs metadata and access control, it does not physically store data. Instead, actual data resides in cloud storage such as Azure Data Lake Storage (ADLS). A managed location in Unity Catalog defines where data and metadata for managed tables are stored. Managed locations can be set at the metastore, catalog, or schema level, allowing granular isolation.
For example, the following command creates a catalog finance_dev with a managed location in the dev container and finance path:
CREATE CATALOG IF NOT EXISTS finance_dev
MANAGED LOCATION 'abfss://dev@<storage-account>.dfs.core.windows.net/finance';All tables and views created under finance_dev will, by default, be stored in the finance directory unless a more specific path is defined. For example, to set a dedicated location for the bronze schema within the same catalog:
CREATE SCHEMA finance_dev.bronze
MANAGED LOCATION 'abfss://dev@myunitystorage.dfs.core.windows.net/finance/bronze';Note: External tables reference data stored outside managed locations—useful for integrating existing datasets without migration.
Centralized Lakehouse Architecture
In a Databricks account, only one Unity Catalog metastore can exist per region. By default, the first workspace created in that region hosts the metastore and a corresponding managed storage account within the Databricks-managed resource group. This default setup can introduce operational complexity—especially if that workspace is later decommissioned.
To address this, it is best practice to centralize the metastore and landing storage in a shared resource group (e.g., rg-lakehouse-shared). This design improves governance, simplifies lifecycle management, and separates platform-level assets from workspace-level resources.
The diagram below illustrates this centralized storage model, where both metastore and landing containers are provisioned in a shared resource group and securely accessed by Databricks via access connectors:
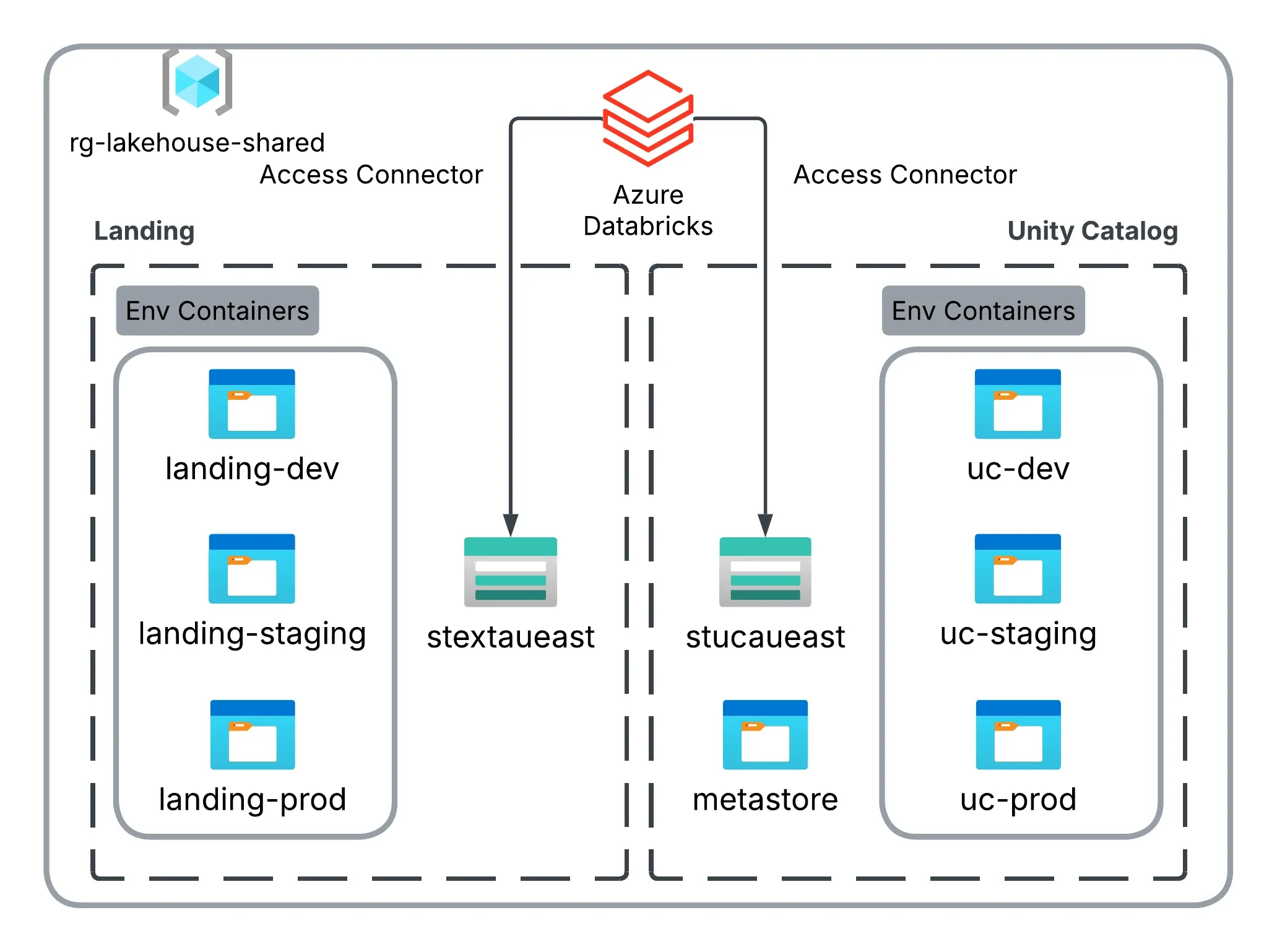
In this setup:
uc-dev,uc-staging, anduc-prodcontainers are root locations for Unity Catalog catalogs in each environment.- An additional `metastore“ container serves as the metastore root for catalogs without specified managed locations.
landing-dev,landing-staging, andlanding-prodcontainers are used for landing data per environment.
This approach keeps data organized, enforces consistent governance and security, and supports clean environment isolation—ensuring scalability and compliance across the entire Databricks Lakehouse platform.
Terraform Modules
Databricks provides a Terraform examples repository with reference implementations for deploying Databricks workspaces and resources across Azure, AWS, and GCP. Our Lakehouse platform builds on the Lakehouse Terraform blueprint, which provisions a complete Databricks Lakehouse environment with Unity Catalog and supporting infrastructure.
Core Infrastructure Modules
| Module | Purpose | Key Responsibilities |
|---|---|---|
| adb-lakehouse | Core Lakehouse infrastructure | - Deploys Databricks workspace - Creates networking (VNet, subnets, NSG) - Sets up ADF, Key Vault, and storage |
| adb-uc-metastore | Centralized Unity Catalog metastore | - Creates shared metastore and access connector - Configures permissions shared across environments |
| adb-lakehouse-uc | Workspace-level Unity Catalog setup | - Defines catalogs, schemas, storage credentials, external locations |
| uc-idf-assignment | Identity & access management | - Assigns service principals and workspace-level roles |
| adb-clusters | Compute and SQL provisioning | - Creates clusters, SQL endpoints, and cluster policies |
These modules are orchestrated together to build a scalable, multi-environment Lakehouse foundation. The design aligns with Infrastructure-as-Code best practices:
- Reusability – Common modules reused across dev, staging, and prod.
- Separation of Concerns – Each module handles a distinct functional layer.
- Parameterization – Environment-specific values managed via
terraform.tfvars. - Dependency Management – Clear provisioning order (e.g., metastore before data assets).
Multiple Environments
For environment management, three approaches were considered:
- Terraform workspaces: Simple but limited isolation.
- Directory-based layouts: Clear separation using dedicated folders and state files.
- Separate repositories/state backends: Maximum isolation with higher operational overhead.
We adopted the directory-based layout with remote state stored in Azure Blob Storage, balancing isolation, simplicity, and maintainability.
.
├── environments
│ ├── dev
│ ├── prod
│ └── staging
└── modules
├── adb-clusters
├── adb-lakehouse
├── adb-lakehouse-uc
├── adb-uc-metastore
└── uc-idf-assignmentEach environment (dev, staging, and prod) has identical file structures:
backend.tf- Remote state configurationterraform.tfvars- Environment-specific variablesmain.tf- Module calls and resource definitionsvariables.tf,providers.tf,outputs.tf,data.tf
Each environment uses isolated Terraform state stored in Azure Storage:
terraform {
backend "azurerm" {
resource_group_name = "rg-lakehouse-tfstate"
storage_account_name = "stlakehousetfstate"
container_name = "tfstate"
key = "dev.terraform.tfstate" # or staging/prod
use_azuread_auth = true
}
}This ensures:
- Team Collaboration: Shared state accessible to all members.
- State Locking: Prevents concurrent modifications.
- Environment Isolation: Separate state files for each environment.
- Backup: Azure Storage redundancy ensures durability.
Shared and Environment-Specific Resources
Some resources are shared across all environments (e.g., the Unity Catalog metastore), while others are created per environment. This structure enables centralized governance with isolated compute environments.
| Category | Resources |
|---|---|
| Shared Resources (Created once and shared across environments) | - Unity Catalog metastore with centralized metadata - Landing zone storage account - Access connectors for authentication |
| Per-Environment Resources (Created separately for dev, staging, and prod) | - Dedicated Databricks workspaces - Environment-specific containers - Independent VNets and security groups - Separate storage credentials and external locations |
Shared Resource Example
Shared resources are created in the dev environment and imported in staging and prod. For example, the landing storage account is created in adb-lakehouse-uc/uc-data-assets/uc-data-assets.tf. Based on deployment_mode, the resource is either created (in dev) or imported (in staging/prod).
resource "azurerm_storage_account" "landing" {
count = var.deployment_mode == "dev" ? 1 : 0
name = var.landing_storage_account_name
resource_group_name = var.landing_storage_account_rg
location = var.landing_storage_account_location
account_tier = "Standard"
account_replication_type = "LRS"
is_hns_enabled = true
}
data "azurerm_storage_account" "landing" {
count = var.deployment_mode == "dev" ? 0 : 1
name = var.landing_storage_account_name
resource_group_name = var.landing_storage_account_rg
}To reference this storage account consistently, locals define its attributes regardless of creation or import:
locals {
landing_storage_account_id = var.deployment_mode == "dev" ? azurerm_storage_account.landing[0].id : data.azurerm_storage_account.landing[0].id
landing_storage_account_name = var.deployment_mode == "dev" ? azurerm_storage_account.landing[0].name : data.azurerm_storage_account.landing[0].name
landing_storage_account_location = var.deployment_mode == "dev" ? azurerm_storage_account.landing[0].location : data.azurerm_storage_account.landing[0].location
landing_storage_account_rg = var.landing_storage_account_rg
}Per-Environment Resource Example
The following example shows creation of per-environment containers (landing-dev, landing-staging, landing-prod) using environment variables:
resource "databricks_external_location" "landing" {
name = "landing-${var.environment_name}"
url = "abfss://landing-${var.environment_name}@${local.landing_storage_account_name}.dfs.core.windows.net/"
credential_name = databricks_storage_credential.landing.name
depends_on = [azurerm_storage_container.landing]
isolation_mode = "ISOLATION_MODE_ISOLATED"
}Unity Catalog Implementation
Databricks requires Unity Catalog and Landing containers to be defined as external locations with appropriate storage credentials. External locations, storage credentials, and catalogs are provisioned in a layered, environment-specific architecture.
resource "azurerm_storage_container" "unity_catalog" {
name = var.environment_name
storage_account_id = var.metastore_storage_account_id
container_access_type = "private"
}
resource "databricks_storage_credential" "unity_catalog" {
name = "${var.metastore_storage_credential_name}-${var.environment_name}"
azure_managed_identity {
access_connector_id = var.metastore_access_connector_id
}
isolation_mode = "ISOLATION_MODE_ISOLATED"
}
resource "databricks_external_location" "unity_catalog" {
name = "unity-catalog-${var.environment_name}"
url = "abfss://${var.environment_name}@${var.metastore_storage_account_name}.dfs.core.windows.net/"
credential_name = databricks_storage_credential.unity_catalog.name
isolation_mode = "ISOLATION_MODE_ISOLATED"
}By setting isolation_mode = "ISOLATED", each catalog is scoped exclusively to its workspace, maintaining environment-level governance boundaries.
resource "databricks_catalog" "bronze_catalog" {
metastore_id = var.metastore_id
name = "bronze_${var.environment_name}"
storage_root = "abfss://${var.environment_name}@${var.metastore_storage_account_name}.dfs.core.windows.net/bronze/"
isolation_mode = "ISOLATED"
depends_on = [databricks_external_location.unity_catalog]
}
resource "databricks_workspace_binding" "bronze" {
securable_name = databricks_catalog.bronze_catalog.name
workspace_id = var.workspace_id
}Azure Resource Organization
Below is the Azure resource structure. The rg-lakehouse-tfstate group is manually created to host Terraform state containers. Shared Lakehouse storage resides in rg-lakehouse-shared.
# Common resources
rg-lakehouse-tfstate/
├── sttfstate (Storage account for Terraform states)
│ ├── tfstate-lakehouse
│ ├── dev.terraform.tfstate
│ ├── staging.terraform.tfstate
│ └── prod.terraform.tfstate
# Shared resources
rg-lakehouse-shared/
├── stextauaest (Landing zone storage)
├── stucauaest (Metastore storage)
├── ac-landing-aueast (Access connector)
└── ac-metastore-aueast (Access connector)
# Per-environment resources
rg-lakehouse-{env}/
├── dbw-lakehouse-{env} (Databricks workspace)
├── VNET-lakehouse-{env} (Virtual network)
├── nat-gateway-lakehouse-{env} (NAT gateway)
└── databricks-nsg-lakehouse-{env} (Security group)
# Managed by Databricks
dbw-lakehouse-{env}-managed-rg/
└── (Databricks-managed resources)Summary
This Terraform-based Lakehouse deployment approach ensures consistent, scalable, and auditable provisioning across environments. Its modular design and clear separation of shared and environment-specific resources create a strong foundation for CI/CD automation and future expansion into advanced data and AI workloads.
CI/CD and Automation: GitOps for Infrastructure
To ensure consistency, repeatability, and compliance across environments, our Databricks Lakehouse infrastructure is deployed using a GitOps-based CI/CD pipeline powered by Terraform and GitHub Actions. This approach enables automated validation, deployment, and governance for multi-environment infrastructure-as-code.
The GitOps Workflow
┌─ Pull Request ─┐ ┌─ Main Branch ─┐ ┌─ Deployment ─┐
│ │ │ │ │ │
│ • Terraform │───▶│ • Auto Deploy │───▶│ • Dev (Auto) │
│ Validation │ │ to Dev │ │ • Staging │
│ • Multi-env │ │ • Manual │ │ (Manual) │
│ Planning │ │ Approval │ │ • Prod │
│ • Security │ │ for Prod │ │ (Manual) │
│ Scanning │ │ │ │ │
└────────────────┘ └───────────────┘ └──────────────┘Pipeline Implementation
1. CI Pipeline: Validation and Testing
The CI workflow (.github/workflows/ci.yml) runs on every pull request to the main branch. It validates Terraform syntax, initializes configurations, and generates plans for each environment.
name: CI - Infrastructure Validation
on:
pull_request:
branches: [main]
jobs:
terraform-validation:
runs-on: ubuntu-latest
strategy:
matrix:
environment: [dev, staging, prod]
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Terraform
uses: hashicorp/setup-terraform@v3
with:
terraform_version: 1.5.7
- name: Terraform Format Check
run: terraform fmt -check -recursive
- name: Initialize Terraform
run: |
cd environments/${{ matrix.environment }}
terraform init
- name: Validate Configuration
run: |
cd environments/${{ matrix.environment }}
terraform validate
- name: Plan Infrastructure
run: |
cd environments/${{ matrix.environment }}
terraform plan -out=tfplan
- name: Upload Plan Artifact
uses: actions/upload-artifact@v4
with:
name: tfplan-${{ matrix.environment }}
path: environments/${{ matrix.environment }}/tfplan2. CD Pipeline: Automated Deployment
The CD workflow (.github/workflows/cd.yml) handles environment deployments. Development is auto-deployed, while staging and production require manual approval through protected environments.
name: CD - Infrastructure Deployment
on:
push:
branches: [main]
jobs:
deploy-dev:
runs-on: ubuntu-latest
environment: dev
if: github.ref == 'refs/heads/main'
steps:
- name: Deploy to Development
run: |
cd environments/dev
terraform apply -auto-approve
deploy-staging:
needs: deploy-dev
runs-on: ubuntu-latest
environment: staging # Protected environment with manual approval
steps:
- name: Deploy to Staging
run: |
cd environments/staging
terraform apply -auto-approve
deploy-prod:
needs: deploy-staging
runs-on: ubuntu-latest
environment: production # Protected environment with manual approval
steps:
- name: Deploy to Production
run: |
cd environments/prod
terraform apply -auto-approveAuthentication and Security
GitHub Actions authenticate to Azure using a Service Principal or OIDC federation. The OIDC method is preferred for passwordless, short-lived tokens.
GitHub Secrets
ARM_CLIENT_ID="<azure-client-id>"
ARM_CLIENT_SECRET="<azure-client-secret>"
ARM_SUBSCRIPTION_ID="<azure-subscription-id>"
ARM_TENANT_ID="<azure-tenant-id>"Security best practices implemented:
- Service principal or OIDC with least-privilege permissions
- Manual approval gates for staging and production
- Plan artifacts retained for audit and rollback
- No hardcoded credentials in configuration files
- Terraform state stored securely in Azure Storage with encryption and blob locking
Development Workflow
I adopted a hybrid workflow combining local development for fast iteration and automated pipelines for promotion to higher environments.
Local Development (Dev Environment)
# Initialize and test locally
source .env
tfenv install 1.5.7
cd environments/dev
terraform plan && terraform apply
# Verify no drift before PR
terraform plan
# Submit for CI validation
git push origin feature-branchCI/CD: Dev Deployment + Staging/Prod Build
- All changes must go through CI/CD pipelines.
- Manual approvals required for deployment.
- Branch protection rules enforce CI validation before merge.
Lessons Learned and Conclusion
Building a modern data lakehouse platform requires balancing cutting-edge technology with proven engineering practices. Throughout this project, several key lessons emerged that can guide future implementations.
Scope and Boundaries of IaC
While Terraform enables consistency, repeatability, and automation, not every configuration needs to be codified.
For a small team or during early development stages, it can be more pragmatic to manage user groups, access control lists, or workspace permissions directly within the Databricks UI—especially when roles change frequently or when onboarding is still evolving.
The key is finding a balance between automation and operational flexibility:
| Terraform-managed | UI-managed / Manual |
|---|---|
| Workspace provisioning and configuration | Ad-hoc group membership changes |
| Unity Catalog, storage credentials, external locations | Temporary access grants for experiments |
| CI/CD pipelines, service principals, network resources | Non-critical feature toggles or workspace settings |
| Data governance policies and catalogs | User-driven workspace configurations |
Over time, as the team and platform mature, more of these manually managed aspects can be migrated into IaC for stronger governance and auditability.
Key Lessons Learned
Shared Resource Management
The initial design created shared resources (e.g., Unity Catalog metastore, storage accounts) within the dev environment and imported them into staging and prod.
A better pattern would be to provision shared resources through a dedicated Terraform module that executes before any environment-specific deployment. This ensures consistency and clear separation between shared and isolated resources.Consistent Authentication Across Local and CI/CD
Using the same Azure Service Principal for both local and automated deployments ensures resource ownership and permissions remain consistent. This also simplifies debugging and traceability across environments.
Guiding Principles for Future Enhancements
- Architecture First – Design for environment isolation, security, and governance from day one.
- Automate Everything (with Intention) – Adopt Infrastructure as Code and GitOps to eliminate manual errors, but be deliberate about what’s worth automating.
- Security by Design – Implement least privilege, centralized identity, and Unity Catalog-based governance.
- Operational Excellence – Invest in monitoring, cost optimization, and clear workflows for long-term sustainability.